Industry
AI / Multimodal Systems / Applied Computer Vision
Client
Multimodal AI Systems Venture
Designing a Multimodal AI Agent and Deterministic State Management

Bridging Generative AI with Deterministic Interface Logic My Role
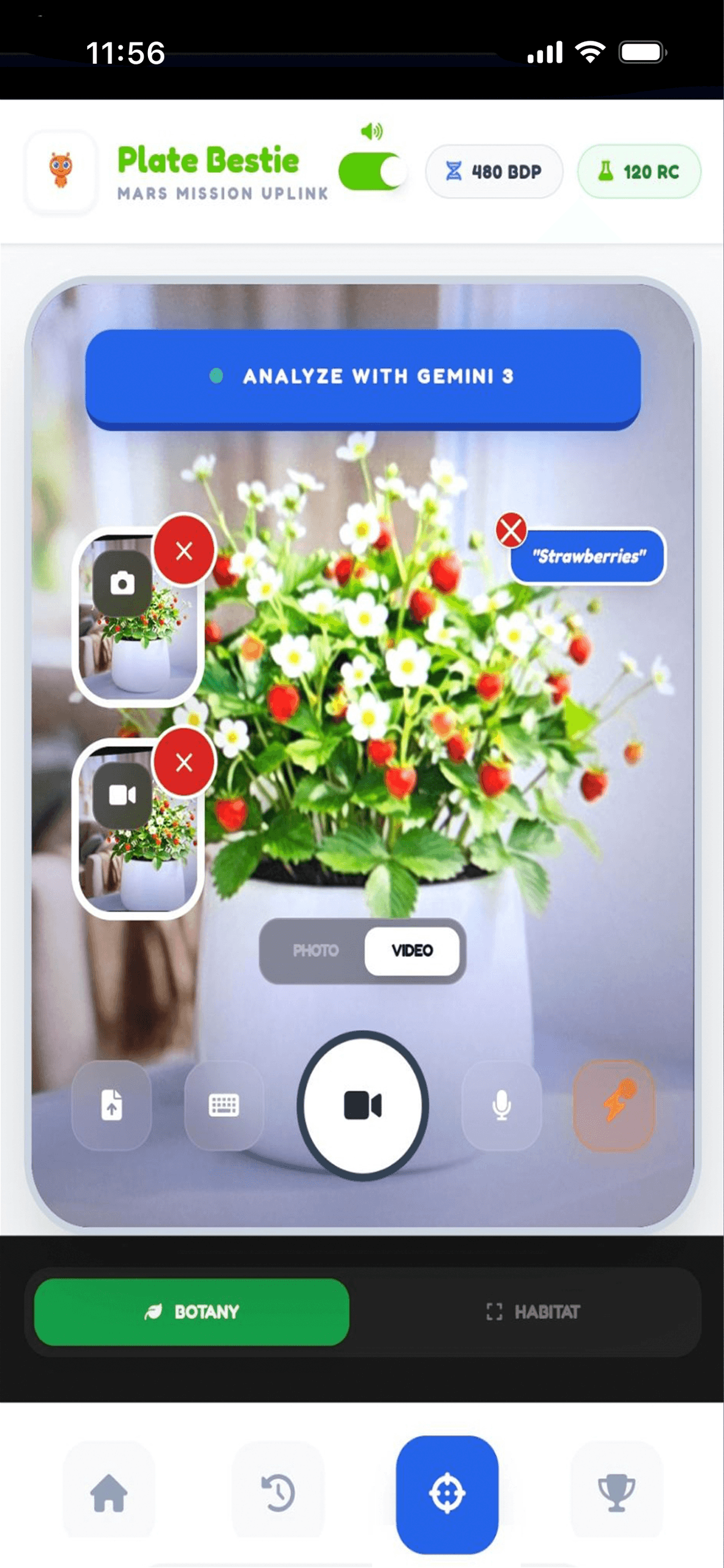
Product Designer & Systems Architect PROBLEM CONTEXT — In extended agentic workflows, large language models often lose environmental context, resulting in unstable UI behavior and conversational drift. Plate Bestie addresses this “state integrity” challenge by constraining model outputs into strict JSON schemas that govern UI state transitions. CONCEPT OVERVIEW — Plate Bestie is a multimodal AI agent built on Gemini 3 Flash that unifies vision, voice, text, video, and structured outputs into a deterministic interaction loop. Rather than treating the model as a chatbot, the system positions it as a perception engine — translating environmental signals into persistent, verifiable interface artifacts. The result is an agent that maintains consistent state across multimodal inputs while ensuring UI updates occur only when predefined confidence thresholds are met. SCALING TO AMBIENT & WEARABLE HARDWARE (GLASSES) — While currently prototyped for mobile, the underlying deterministic state logic was architected to translate seamlessly to "eyes-busy" device experiences (like XR and Smart Glasses). By decoupling the AI's reasoning from a purely visual UI, the system supports: • Non-Visual State Verifiability: The deterministic JSON schemas map directly to a 3-tier audio/haptic taxonomy (Confirmation, Ambiguity, Hallucination-Risk), allowing users to verify agentic actions without looking at a screen. • Spatial Grounding via Continuous Vision: Integrating Gemini’s multimodal vision capabilities allows the agent to use spatial anchoring. The system binds the deterministic UI state to physical objects in the user's field of view, drastically reducing the "intent-gap." • Low-Latency Interruption (Graceful Degradation): In wearable contexts, user safety requires instant overrides. The state-management loop allows for instantaneous interruption (e.g., via gaze shift or voice command), killing the inference stream without requiring visual menu navigation.